This is the last post in my conversion rate prediction series, where I discuss various techniques for grouping and sorting consumer products based on their similarity level. The end goal is to accrue enough historical advertising data to accurately predict the future performance of individual PPC keywords.
In my last post, I discussed utilizing the cosine similarity of OpenAI Large three text embeddings and the results from BM25 search to rank the similarity of products based on their product titles. On closer examination, this technique falls short for many examples for a simple reason. Text embeddings and MB25 search do not know which words in a product title are most important.
In this blog post, I will explore using an LLM to normalize product attributes and then using those normalized attributes to replace the BM25 search with a new scoring mechanism that gives more weight to the most important attributes.
The Problem
During this series, I have focused on power tools. Let’s keep up the tradition and examine some real-world issues with OpenAI text-embedding-3-large (#37 on the Hugging Face retrieval leaderboard).
As an overview, I aim to group and sort products based on similarity. In a previous post, I grouped products based on taxonomy hierarchy and product prices. Now, I will augment this approach by sorting products by their similarity such that all “jig saws” are beside each other and reciprocating saws ranked close to “jig saws” but are not co-mingled.
Unfortunately, the cosine similarity of product titles will not be enough. Consider the following…
There is a .9 cosine similarity between the titles of these two products!


There is a .61 cosine similarity between the jig saw and this cordless vacuum!

Alas, .59 is lowest cosine similarity and it is between two jig saws!

A Solution
LLMs excel at interpreting and synthesizing text. Achieving consistent, normalized responses from Gen-AI chat requests is a more complex problem, and as you will see, we will have to deal with it in this research.
If you follow the latest LLM research, you may be aware of many initiatives to incorporate knowledge graphs into LLM workflows. Here, I will take a somewhat similar approach by leveraging OpenAI to extract and quasi-normalize product attributes. I will use those attributes to help score product similarity.
The Gen-AI prompt technique I am using to extract attributes is called few shot prompting and involves giving three examples of expected JSON output given product JSON inputs.
I start out with a system prompt:
You are a data librarian in charge of normalizing the attributes of consumer products.
Your goal is to standardize consumer product attributes to facilitate the comparison of
similar products. You will always use the same spelling when describing the same attribute.
You will be given a short product description and asked to extract all attributes from this description.
You will only interpret the text and transform it into normalized attribute names. Your goal is consistency
between consumer product attributes.
Then I utilize the following few-shot user prompt:
Your task is to extract product attributes from a list of product descriptions and return those attributes in a normalized, consistent JSON format. The following few shot examples will illustrate how the task should be performed.
{ “guid”: “UZGOIUV5REAI”, “product description” : “6-CIA 115 Volt 1/3 HP 2760 GPH Cast Iron Submersible Sump Pump with Integral Diaphragm Switch 10-Ft. Cord Blue Little Giant 506158”}
{
“guid” : “UZGOIUV5REAI”,
“product description” : “6-CIA 115 Volt 1/3 HP 2760 GPH Cast Iron Submersible Sump Pump with Integral Diaphragm Switch 10-Ft. Cord Blue Little Giant 506158”,
“manufacturer” : “little giant”,
“manufacturer part number” : “506158”,
“material” : “cast iron”,
“product type” : “sump pump”,
“voltage” : “115 volts”,
“power” : “1/3 hp”,
“capacity” : “2760 gph”
}{ “guid”: “185AR7Q3XY05R”, “product description” : “BOSCH 12V Max Cordless Drill/Driver and Impact Driver Combo Kit with Bit Holder”}
{
“guid”: “185AR7Q3XY05R”,
“product description” : “BOSCH 12V Max Cordless Drill/Driver and Impact Driver Combo Kit with Bit Holder”,
“manufacturer” : “bosch”,
“product type” : “drill driver combo kit”,
“voltage” : “12 volts”,
}{ “guid”: “19Z8KL7A8E75M”, “product description” : “Vacmaster VBV1210, 12-Gallon* 5 Peak HP** Wet/Dry Shop Vacuum with Detachable Blower, Blue – Cleva North America”}
{
“guid” : “19Z8KL7A8E75M”,
“product description”, “Vacmaster VBV1210, 12-Gallon* 5 Peak HP** Wet/Dry Shop Vacuum with Detachable Blower, Blue – Cleva North America”
“manufacturer” : “cleva north america”,
“manufacturer part number” : “vbv1210”,
“product brand” : “vacmaster”
“product type” : “shop vacuum”,
“capacity” : “12 gallons”,
“power” : “5 hp”
}Here are the product descriptions you should normalize and return in a JSON object that
utilizes the following json schema:
{
“product attributes” : [{ }, {} ]
}
This inference technique yields a greater than 99.99% success rate for “product type” extraction, but the value for product types is dependent on the product title. For example, two jig saw product types might be “cordless jig saw” and “jig saw,” depending on how the title is constructed.
The above OpenAI prompt yields the following for the products mentioned in the previous section.
{ "norm_attributes": { "guid": "GBCHPW2IILK1", "title": "18V LXT Lithium-Ion Cordless Jig Saw Tool Only Makita XVJ03Z", "manufacturer": "makita", "manufacturer part number": "xvj03z", "product type": "cordless jig saw", "voltage": "18 volts" } }
Note how the second jig saw has similar wording for product type. The LLM has expanded 20V to “20 volts.” The power type of “tool only” is interesting but not completely incorrect. This item does NOT have a battery, so it has no power source!
{
"norm_attributes": {
"guid": "9TIDAFQMJ9HG",
"title": "20V MAX Jig Saw Tool Only DeWalt DCS331B",
"manufacturer": "dewalt",
"product type": "jig saw",
"voltage": "20 volts",
"power type": "tool only"
}
}
And here is the reciprocating saw. Yes! It is classified as a reciprocating saw! Did you notice that OpenAI expanded “Recipro” to “reciprocating”?
{
"norm_attributes": {
"guid": "NHN0SM4XDDE3",
"title": "18V LXT Lithium-Ion Brushless Cordless Recipro Saw Tool Only Makita XRJ05Z",
"manufacturer": "makita",
"voltage": "18 volts",
"product type": "reciprocating saw",
"power": "brushless"
}
}
Lastly, here is the cordless vacuum. “Compact Vacuum” is perhaps not optimal, but we can work with it!
{
"norm_attributes": {
"guid": "U0RIDIHQUS9P",
"title": "Milwaukee M12 12-Volt Lithium-Ion Cordless Compact Vacuum Tool-Only 0850-20",
"manufacturer": "milwaukee",
"manufacturer part number": "0850-20",
"product type": "compact vacuum",
"voltage": "12 volts"
}
}
Evaluating My Options
Let’s evaluate where we are now. We have cosine similarity of product titles, which will help us get in the ballpark. We have product types being extracted with the potential for exact matches but also partial matches. Lastly, we have other attributes such as voltage, manufacturer, power, and, quite frankly, hundreds of other attributes because I did not lock down the OpenAI response with a JSON schema.
The similarity algorithm I originally envisioned was as follows: (spoiler alert! this is not the final solution):
- Use cosine similarity to group products and get us in the ballpark.
- Add any missing products that have exact match product types.
- Create three sorted lists: one sorted by cosine similarity, one sorted by product type similarity, and the last one sorted by an aggregate attribute score. We will use product type similarity in the aggregate attribute score but also break it out into its own list to give it more weight.
- Use reciprocal rank fusion to create an all-encompassing aggregate similarity score.
- Profit!
Our outstanding problem is the non-normalized nature of attribute names and values. Attribute names can be locked down with a JSON schema and model fine-tuning. I recommend NOT locking down attribute names until you have studied the output extensively. The LLM will help guide you in the correct direction and highlight attributes you may not have considered.
Attribute values (the “cordless jig saw” vs. “jig saw” problem) could be addressed by creating synonym lookups, base model training, model fine-tuning, or a looser matching technique.
I recently solved the different wording of the same product types via a synonym lookup, but the number of products was less than 15,000. To create synonyms at scale, consumer products can be grouped by UPCs or the combination of manufacturer name and manufacturer part numbers. With this grouping mechanism, you can match identical products from different retailers. The product titles are not standardized across retailers. You can generate a list of potential synonyms for a single product by running all retailer title permutations through the attribute extraction Gen-AI prompt. Another layer of review after synonym generation is recommended.
This blog post’s solution should work with all consumer products on FindersCheapers.com, e.g., 150 million permutations (1 billion+ if you process all title permutations). Due to the scale of the problem and my limited financial resources, I will compute attribute similarity via a fuzzy match.
Findings
As is often the case, my dream of a single mathematical score that perfectly defined the level of similarity between products crashed on the shores of near-infinite textual variation. The product type was, by far, the most essential attribute. The cosine similarity of title embeddings came up short because, as we already illustrated, different products will have as little as a one-word difference in their titles. Attributes such as voltage, power, and manufacturer name are the same across dissimilar products. These attributes ended up being the noisiest by far.
I found Jaccard string similarity worked best for comparing product-type strings. I tried Jaccard, Levenshtein, Jaro-Winkler, and Jaro. Jaro-Winkler was discarded early because it favored similarity at the start of strings. For the “cordless” drill|saw|wrench|… examples, this was not a desirable feature. The simple test below illustrates the string similarity performance for the ‘cordless jig saw” to ‘jig saw’ comparison problem.
Jaccard : 'cordless jig saw' vs 'jig saw' = 0.67
Jaccard : 'cordless jig saw' vs 'cordless jaw saw' = 0.50
Jaccard : 'cordless jig saw' vs 'cordless miter saw' = 0.50
Jaccard : 'cordless jig saw' vs 'cordless drill' = 0.25
# With Levenshtein, smaller scores are more similar
Levenshtein : 'cordless jig saw' vs 'cordless drill' = 7.00
Levenshtein : 'cordless jig saw' vs 'jig saw' = 9.00
Jaro : 'cordless jig saw' vs 'cordless drill' = 0.78
Jaro : 'cordless jig saw' vs 'jig saw' = 0.30
The most useful method was to layer similarity levels, akin to the taxonomy layering I mentioned in a previous post. To generate accurate results, I created a layer sorted by ONLY the Jaccard similarity of product types where the Jaccard score was greater than zero. I then appended a list sorted by the reciprocal rank of the title cosine and attribute scores.
In the diagram below, I show a single product and its list of similar products to illustrate what my similarity algorithm calculates. I am showing only the “product type” strings in the diagram.
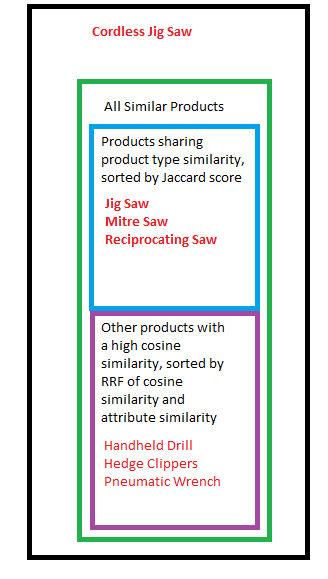
Here is a step by step overview of how the algorithm operates:
- For every product title, compute the cosine similarity of its OpenAI Large 3 embedding with every other product title
- For every product title, call the OpenAI chat completions API and extract all possible product attributes
- For every product title, build a list called “all_similar” products which is comprised of all product titles that had a cosine similarity score > .58.
- For every product, compute the Jaccard similarity of the “product type” attribute. (e.g. “Cordless Jig Saw”, “Miter Saw”, “Jig Saw”, etc.) with every other product.
- For every product, if there are other products with product types that have a very high Jaccard similarity but with title cosine similarity score < .58, add them to the products “all similar” list. We now how our complete list of similar products.
- For every product, iterate through each product in the “all_similar” product list and compute the Jaccard similarity of all attributes (e.g. 12 volts, 12 v, 25 GPM, 25 Gallons Per Minute, etc)
- For every product, sort its corresponding “all_similar” list by the cosine similarity and remember the index of each.
- For every product, sort its “all_similar” by the composite attribute similarity and remember the index of each.
- For every product, create a new array and only add similar products who’s product type similarity is greater than zero. Sort it by product type similarity
- For every product, create a new array and add products with a product type similarity of zero. Sort this array by the reciprocal rank fusion score of the cosine similarity rank and the composite attribute rank.
- For every product, combine both new arrays, this is your final similar product list, sorted by relevance.
Here is a real-world example with the corresponding product titles:
For this product:
18V LXT Lithium-Ion Cordless Jig Saw Tool Only Makita XVJ03Z (product type = “cordless jig saw”)
The following products were computed, in order:
- 20V MAX Jig Saw Tool Only DeWalt DCS331B (product type = “jig saw”)
- 20V MAX XR Jig Saw 3 200 Blade Speed Cordless Brushless Motor LED Light Bare Tool Only DeWalt DCS334B (product type = “jig saw”)
- 120V 7.0-Amp Corded Top-Handle Jig Saw Bosch JS470E (product type = “jig saw”)
- 20V MAX Router Tool and Jig Saw Cordless Woodworking 2-Tool Set with Battery and Charger DeWalt DCK201P1 (product type = “router and jig saw set”)
- M18 Fuel 6 1/2 Inch Circular Saw Brushless Tool Only Milwaukee 2730-20″ (product type = “circular saw”)
- 48V 7-1/4 Inch TRUEHVL Cordless Worm Drive saw Circular Saw Kit with 1 Battery SKIL SPTH77M-11 (product type = “circular saw”)
- Milwaukee 2738-20 M18 18-Volt FUEL Lithium-Ion Brushless Cordless 7 inch Variable Speed Polisher Tool-Only Milwaukee Electric Tool Corporation (product type = “cordless polisher”)
- 20V MAX Circular Saw 6-1/2-Inch Cordless Tool Only DeWalt DCS565B (product type = “circular saw”)
- …
Conclusion
For my use case, where I predict future performance based on sparse historical data, the improved sorting of similar products will offer an incremental improvement over my traditional taxonomy-level grouping of unsorted lists. Product pricing is still critical when grouping similar products. Acknowledging that different product types will have different conversion rates and the ability to group by this difference is a valuable addition. For example, an “air wrench” will have a different conversion rate from an “impact wrench” due to the different user segments who would purchase said products.
Product type sorting is a vast improvement over unsorted taxonomy node children, but it is imperfect. The results would have been better if all attribute values were fully normalized. I will continue researching the relationships between ngrams in product titles and how those ngrams influence conversion rates. For example, is there a conversion rate difference between cordless and corded power tools? The similarity of products and the impact product attributes have on conversion rates is a complex problem, and this blog post is just scratching the surface.
All of the refinement methods I mentioned in my “evaluating my options” section will probably need to be implemented. e.g., Training an LLM base model with product data, leveraging unique identifiers to identify product type synonyms, and then fine-tuning the LLM via reinforcement learning using the synonym list. After the LLM has been tuned to give more normalized and consistent attributes, a set of comparison rules that move beyond my two-layer approach would need to be developed. For example, Dewalt products convert differently than “Harbor Freight” products, and the manufacturer’s name should be considered when grouping products.


Leave a comment