Introduction
My previous post discussed a conversion rate prediction technique for very low-volume PPC keywords that leveraged taxonomy hierarchies and product prices to group similar products. These product groupings were used to make statistically sound conversion rate predictions. My next series of blog posts will delve into techniques that leverage Gen-AI to more accurately group consumer products. These techniques will augment my previously discussed grouping algorithm. The ad network, PPC keyword generation algorithm, and product price will still play a role in the product groupings.
The Problem
With my business, I find many use cases where I need to group products using free-form text. Product titles are my primary source for product information because they typically condense important product attributes into a short sentence fragment. Product descriptions, on the other hand, tend to have a lot of unnecessary word noise.
There are an almost infinite number of ways a retailer can describe the same product. While shopping feeds can provide normalized data such as the Manufacturer Name, UPCs, Manufacturer Part Numbers, and Taxonomy Nodes, the accuracy and completeness could be better. One of the issues is an incentive not to share pricing information that can be easily correlated to one’s competitors, especially if you are not the price leader. Also, some manufacturers, such as Wal-Mart, will have product versions that differ slightly in functionality as a cost-saving measure. Consider the product titles from four different websites for the same Dewalt Hammer Drill:
- Home Depot – 10 Amp 1/2 in. Variable Speed Reversible Pistol Grip Hammer Drill
- Lowes – DEWALT 1/2-in 10-Amp Variable Speed Corded Hammer Drill
- Ace Hardware – DeWalt 10 amps 1/2 in. VSR Corded Hammer Drill
- ebay – Hammer Drill, 1/2-Inch, 10-Amp, Pistol Grip () – DeWalt DWD520
Note how the attributes differ. For example, “Variable Speed” is shortened to “VSR” and “inches” is shortened to “in.”. “Pistol Grip” and “Corded” occur in a subset of the titles.
Now consider how five stores describe a competing product from Bosch:
- Home Depot – 7 Amp Corded 1/2 in. Concrete/Masonry Variable Speed Hammer Drill Kit with Hard Case
- Tractor Supply – Bosch 1/2 in. Hammer Drill with Case
- Lowes – Bosch 1/2-in 7-Amp Variable Speed Corded Hammer Drill
- ebay – Bosch 1191VSRK 1/2″ Electric Corded Hammer Drill with Case 7 Amps
- amazon – Bosch 1191VSRK 120-Volt 1/2-Inch Single-Speed Hammer Drill
Product Groupings as a Search Problem
I estimate conversion rates on a product-by-product basis. The product grouping algorithm is as follows:
- Given one+ years of historical advertising data
- Iterate through every product
- Create a list of related products, most similar to least similar.
- Stop creating the list when there is enough historical activity to make a conversion rate prediction
You can think of this grouping approach as a search algorithm. The algorithm searches for the most similar products, starting with the target product. Here is a simple example. I fed the entire Bosh Hammer Drill product title from Home Depot into my search. In this example, the prime candidates for the product grouping would be the first page of search results.
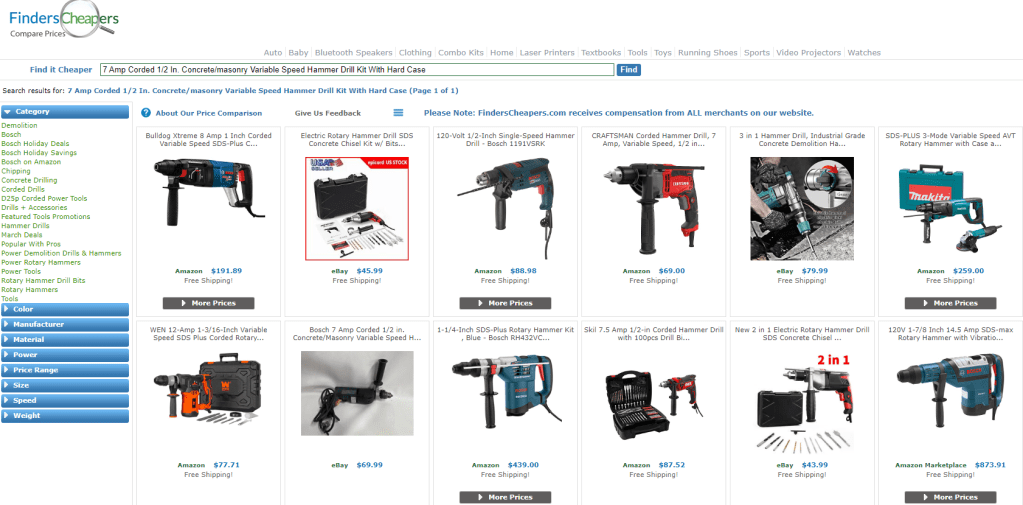
There is constant pressure to produce more accurate conversion rate predictions. A more accurate product grouping could yield a more precise conversion rate prediction, which in turn can result in more sales. So, while BM25 or TF/IDF search scoring might function fairly well, the question becomes, can we gain an extra 10% or 20% in sales by taking groupings to the next level?
Grouping Products with Hybrid Search
With the proliferation of Gen-AI chatbots that rely on retrieval augmented generation (RAG), a wonderfully simple and elegant hybrid scoring methodology known as Reciprocal Rank Fusion has become popular. Here is the research paper that describes the approach. My product grouping problem and the RAG architecture have a common goal. They both seek to identify the best document matches from a text string, typically 7-14 words. My algorithm uses product titles and RAG is using a user submitted chat question.
One popular approach to improve document retrieval accuracy with RAG architectures combines a BM25 search with a vector search. The relevancy scores from two unrelated search engines can only be combined once normalized. The genius of reciprocal rank fusion is the realization that the placement of a document in a search result list (e.g., the array index) can be used as a normalized score. For example:

A whole new world of matching possibilities opens up with an easy-to-implement methodology for combining unrelated relevancy scores.
OpenAI Embeddings Get You In the Ballpark
Here is an introductory article if you are unfamiliar with text embeddings. In January 2024, OpenAI released new embedding models that were significantly improved over their previous ADA embeddings. I have found embedding models that score highly on the Hugging Face Retrieval leaderboard work well for consumer product groupings. I am currently using OpenAI’s text-embedding-3-large for my product title comparisons.
The technique I use to calculate product similarity via embeddings:
- Create a list of product titles
- Call the OpenAI embedding endpoint for each title, requesting text-embedding-3-large
- Build a Numpy array with each title embedding
- Create a copy of the Numpy Array that is transposed
- Call Numpy.dot for the dot product of both arrays. (dot product is same as cosine similarity for OpenAI vectors)
- Establish a cosine similarity threshold that signifies products are similar enough to be grouped
A single large-3 embedding has 3,072 dimensions. Calculating cosine similarity between just two vectors at a time for a huge dataset will, as my friend Dr. Stephyn Butcher says, “take until the heat death of the universe”. To avoid such a fate, I am creating large matrices and calling np.dot as few times as possible. Batch calculating similarities with large matrices drastically improves performance.
In the example below, I have three distinct consumer products and merchant-specific variations in their descriptions. The products are a Dewalt Hammer Drill, a Bosch Hammer Drill, and a Dewalt Claw Hammer. The Bosh and Dewalt Hammer drills should appear in the same product grouping. The Dewalt Claw Hammer should not appear in the same grouping. Note that product titles that represent the same products are color-coded with blue, purple, and red text.

In this example, the threshold I chose was .63. The cells with green backgrounds passed the minimal threshold. This minimum cosine similarity value was selected by manually rating text pairs (thumbs up, thumbs down) and then analyzing the ratings to determine what score threshold provided the desired results. Optimal score thresholds will undoubtedly vary based on the task at hand.
OpenAI embeddings can provide a valuable similarity score that helps create product groupings. However, even though the above example gives the illusion that they are flawless, these embeddings are imperfect. With only 3,072 dimensions, there is a loss in fidelity. Embeddings are approximations that do not necessarily consider the most important words in a product title. Based on my personal experience implementing RAG chat as well as product groupings, I have concluded that the cosine similarity of embeddings should be combined with other similarity scoring algorithms for optimal accuracy.
Conclusion
In this blog post, I introduced the Reciprocal Rank Fusion algorithm and the idea that product groupings could be more precise by combining the BM25 full-text search algorithm and the cosine similarity calculations of a vector search database.
In my next blog post, I will explore utilizing an LLM to extract normalized attributes from a product title and create a new ranking algorithm based on those attributes that can be fed into Reciprocal Rank Fusion scoring.


Leave a comment